八股文收集
C++
虚函数
虚函数,纯虚函数和虚析构函数 [1]
-
C++ 中的虚函数的作用主要是实现了多态的机制。关于多态,简而言之就是用父类型的指针指向其子类的实例,然后通过父类的指针调用实际子类的成员函数。这种技术可以让父类的指针有“多种形态”,这是一种泛型技术。如果调用非虚函数,则无论实际对象是什么类型,都执行基类类型所定义的函数。非虚函数总是在编译时根据调用该函数的对象,引用或指针的类型而确定。如果调用虚函数,则直到运行时才能确定调用哪个函数,运行的虚函数是引用所绑定或指针所指向的对象所属类型定义的版本。虚函数必须是基类的非静态成员函数。虚函数的作用是实现动态联编,也就是在程序的运行阶段动态地选择合适的成员函数,在定义了虚函数后,可以在基类的派生类中对虚函数重新定义,在派生类中重新定义的函数应与虚函数具有相同的形参个数和形参类型。以实现统一的接口,不同定义过程。如果在派生类中没有对虚函数重新定义,则它继承其基类的虚函数。
class Person{ public: //虚函数 virtual void GetName(){ cout<<"PersonName:xiaosi"<<endl; }; }; class Student:public Person{ public: void GetName(){ cout<<"StudentName:xiaosi"<<endl; }; }; int main(){ //指针 Person *person = new Student(); //基类调用子类的函数 person->GetName();//StudentName:xiaosi }虚函数(Virtual Function)是通过一张虚函数表(Virtual Table)来实现的。简称为V-Table。在这个表中,主是要一个类的虚函数的地址表,这张表解决了继承、覆盖的问题,保证其容真实反应实际的函数。这样,在有虚函数的类的实例中这个表被分配在了这个实例的内存中,所以,当我们用父类的指针来操作一个子类的时候,这张虚函数表就显得由为重要了,它就像一个地图一样,指明了实际所应该调用的函数。
-
纯虚函数是在基类中声明的虚函数,它在基类中没有定义,但要求任何派生类都要定义自己的实现方法。在基类中实现纯虚函数的方法是在函数原型后加
=0(virtual void GetName() = 0)。在很多情况下,基类本身生成对象是不合情理的。例如,动物作为一个基类可以派生出老虎、孔雀等子类,但动物本身生成对象明显不合常理。为了解决上述问题,将函数定义为纯虚函数,则编译器要求在派生类中必须予以重写以实现多态性。同时含有纯虚拟函数的类称为抽象类,它不能生成对象。这样就很好地解决了上述两个问题。将函数定义为纯虚函数能够说明,该函数为后代类型提供了可以覆盖的接口,但是这个类中的函数绝不会调用。声明了纯虚函数的类是一个抽象类。所以,用户不能创建类的实例,只能创建它的派生类的实例。必须在继承类中重新声明函数(不要后面的=0)否则该派生类也不能实例化,而且它们在抽象类中往往没有定义。定义纯虚函数的目的在于,使派生类仅仅只是继承函数的接口。纯虚函数的意义,让所有的类对象(主要是派生类对象)都可以执行纯虚函数的动作,但类无法为纯虚函数提供一个合理的缺省实现。所以类纯虚函数的声明就是在告诉子类的设计者,“你必须提供一个纯虚函数的实现,但我不知道你会怎样实现它”。//抽象类 class Person{ public: //纯虚函数 virtual void GetName()=0; }; class Student:public Person{ public: Student(){ }; void GetName(){ cout<<"StudentName:xiaosi"<<endl; }; }; int main(){ Student student; }
引入虚函数带来的问题[4]
虚函数影响效率有两点原因,第一,Cache命中率不够好,一般函数可能编译后的指令就在当前函数地址附近,这样很可能在调用前目标函数代码已经被载入指令cache. 但是虚拟函数不在cache中的概率高。而且一调函数就可能在cache中载入虚函数表,如果这个虚函数又调用其它的虚函数,那么可能又得载入到cache中导致cache被占用,指令和数据的cache命中率下降。 第二点编译器不好优化。因为编译器只知道你要调用的是一个不确定的地址处的函数,没法知道更多细节,也就没法替你做更多优化。
C++ sort 函数的实现
Reference: https://en.wikipedia.org/wiki/Introsort
libstdc++ 和 libc++ 中的 sort函数的实现中,主体部分是使用了 Introsort 算法。
内省排序(英语:Introsort)是由David Musser在1997年设计的排序算法。这个排序算法首先从快速排序开始,当递归深度超过一定深度(深度为排序元素数量的对数值)后转为堆排序。采用这个方法,内省排序既能在常规数据集上实现快速排序的高性能,又能在最坏情况下仍保持 的时间复杂度。由于这两种算法都属于比较排序算法,所以内省排序也是一个比较排序算法。
C++11/14/17/20新特性
C++11新特性
智能指针
unique_ptr
为动态申请的内存提供异常安全
将动态申请内存的所有权传递给某个函数(不能给复制,只能移动)
从某个函数返回动态申请内存的所有权
在容器中保存指针
在那些要不是为了避免不安全的异常问题(以及为了保证指针所指向的对象都被正确地删除释放),我们不可以使用内建指针的情况下,我们可以在容器中保存unique_ptr以代替内建指针
shared_ptr & weak_ptr
当 shared_ref_cnt 被减为0时,自动释放 ptr 指针所指向的对象。当 shared_ref_cnt 与 weak_ref_cnt 都变成0时,才释放 ptr_manage 对象。
如此以来,只要有相关联的 shared_ptr 存在,对象就存在。weak_ptr 不影响对象的生命周期。当用 weak_ptr 访问对象时,对象有可能已被释放了,要先 lock()。
weak_ptr可以保存一个“弱引用”,指向一个已经用shared_ptr进行管理的对象。为了访问这个对象,一个weak_ptr可以通过shared_ptr的构造函数或者是weak_ptr的成员函数lock()转化为一个shared_ptr。当最后一个指向这个对象的shared_ptr退出其生命周期并且这个对象被释放之后,将无法从指向这个对象的weak_ptr获得一个shared_ptr指针,shared_ptr的构造函数会抛出异常,而weak_ptr::lock也会返回一个空指针。
weak_ptr防止循环引用
众所周知,shared_ptr可能造成循环引用问题,那么weak_ptr是怎么解决循环引用问题的呢?看一个例子
class A {
public:
shared_ptr<B> ab;
// 这里可以加上构造/析构函数看下是否能够被调用
};
class B {
public:
shared_ptr<A> ba;
// 这里可以加上构造/析构函数看下是否能够被调用
};
shared_ptr<A> spa = make_shared<A>(); // 定义一个A对象
shared_ptr<B> spb = make_shared<B>(); // 定义一个A对象
spa.ab = spb; //shared_ptr计数成员_Sp_counted_base浅拷贝,use ref++
spb.ba = spa;显然,由于A、B互相引用,都无法释放,造成内存泄漏(示例参考自blog)
怎样打破这种循环引用?cppreference的说法是
std::weak_ptr 的另一用法是打断 std::shared_ptr 所管理的对象组成的环状引用。若这种环被孤立(例如无指向环中的外部共享指针),则 shared_ptr 引用计数无法抵达零,而内存被泄露。能令环中的指针之一为弱指针以避免此情况。
Implement a simple smart pointer (shared_ptr)
It’s designed with two classes. The first is ReferenceCount, it’s used to count the reference number of the object. The second is MySharedPtr, it’s used to manage the object. The MySharedPtr class has a pointer to the ReferenceCount class. When the MySharedPtr class is created, it will create a ReferenceCount class and set the reference number to 1. When the MySharedPtr class is copied, it will increase the reference number of the ReferenceCount class. When the MySharedPtr class is deleted, it will decrease the reference number of the ReferenceCount class. When the reference number of the ReferenceCount class is 0, it will delete the object and the ReferenceCount class.
#include <algorithm>
#include <iostream>
#include <mutex>
using namespace std;
class ReferenceCount{
public:
explicit ReferenceCount(int ref = 1): cnt(ref){
}
void add_ref(){
++cnt;
}
void remove_ref(){
--cnt;
}
[[nodiscard]] unsigned get() const{
return cnt;
}
private:
unsigned int cnt;
};
template<typename T>
class MySharedPtr{
public:
explicit MySharedPtr(T* argPtr): targetPtr(argPtr), cntPtr(new ReferenceCount()){}
MySharedPtr(): targetPtr(nullptr), cntPtr(nullptr){}
MySharedPtr(const MySharedPtr& argSharedPtr): targetPtr(argSharedPtr.targetPtr), cntPtr(argSharedPtr.cntPtr){
m1.lock();
if(cntPtr){
cntPtr->add_ref();
}
m1.unlock();
}
~MySharedPtr(){
m1.lock();
if(cntPtr){
cntPtr->remove_ref();
}
if(!cntPtr->get()){
delete targetPtr;
delete cntPtr;
targetPtr = nullptr;
cntPtr = nullptr;
}
m1.unlock();
}
T* getTargetPtr(){
return targetPtr;
}
ReferenceCount* getReferenceCountPtr(){
return cntPtr;
}
T& operator * (){
return *targetPtr;
}
T* operator -> (){
return targetPtr;
}
private:
mutex m1;
T* targetPtr;
ReferenceCount *cntPtr;
};
int main(){
auto ptr = new pair<int, int>{1, 2};
MySharedPtr<pair<int, int>> ptr1(ptr);
MySharedPtr<pair<int, int>> ptr2(ptr1);
cout << ptr2->first << endl;
cout << (*ptr2).second << endl;
return 0;
}右值引用与移动构造函数
C++14新特性 [2]
函数返回值类型推导
C++14 对函数返回类型推导规则做了优化,先看一段代码:
#include <iostream>
using namespace std;
auto func(int i){
return i;
}
int main(){
cout << func(4) << endl;
return 0;
}使用C++11编译:
~/test$ g++ test.cc -std=c++11
test.cc:5:16: error: ‘func’ function uses ‘auto’ type specifier without trailing return type
auto func(int i) {
^
test.cc:5:16: note: deduced return type only available with -std=c++14 or -std=gnu++14上面的代码使用 C++11 是不能通过编译的,通过编译器输出的信息也可以看见这个特性需要到 C++14 才被支持。
返回值类型推导也可以用在模板中:
#include <iostream>
using namespace std;
template<typename T>
auto func(T t){ return t; }
int main(){
cout << func(4) << endl;
cout << func(3.4) << endl;
return 0;
}注意
- 函数内如果有多个return语句,它们必须返回相同类型,否则编译失败。
auto func(bool flag){ if(flag) return 1; else return 2.3; // error } // inconsistent deduction for auto return type: 'int' and then 'double' - 如果return语句返回初始化列表,返回值类型推导也失败。
auto func(){ return {1, 2, 3}; // error returning initializer list } - 如果函数是虚函数,不能使用返回类型推导。
struct A{ // error: virtual function cannot have deduced return type virtual auto func() { return 1; } } - 返回类型推导可以在前向声明中,但是在使用他们之前,翻译单元中必须能够得到函数定义。
auto f(); // declared, not yet defined. auto f() { return 42; } // defined, return type is int int main(){ cout << f() << endl; } - 返回类型推导可以用在递归函数中,但是递归调用必须以至少一个返回语句作为先导,以便编译器推导出返回类型。
auto sum(int i){ if(i == 1) return i; else return sum(i - 1) + i; }
lambda参数auto
在C++11中,lambda表达式参数需要使用具体的类型声明:
auto f = [](int a) { return a; }在C++14中,对此进行优化,lambda表达式参数可以直接是auto:
auto f = [](auto a){ return a; }
cout << f(1) << endl;
cout << f(2.3f) << endl;变量模板
C++14支持变量模板:
template<class T>
constexpr T pi = T(3.1415926535897932385L);
int main(){
cout << pi(int) << endl;
cout << pi(double) << endl;
}别名模板
C++14 也支持别名模板
template<typename T, typename U>
struct A{
T t;
U u;
};
template<typename T>
using B = A<T, int>;
int main(){
B<double> b;
b.t = 10;
b.u = 20;
cout << b.t << endl;
cout << b.u << endl;
return 0;
}constexpr的限制
C++14 相较于 C++11 对 constexpr 减少了一些限制:
- C++11 中constexpr函数可以递归使用,在 C++14 中可以使用局部变量和循环
constexpr int factorial(int n){ // C++14 和 C++11 均可 return n <= 1 ? 1 : (n * factorial(n - 1)); }constexpr int factorial(int n){ // C++11 中不可以, C++14 中可以 int ret = 0; for(int i = 0; i < n; ++i){ ret += i; } return ret; } - C++11 中 constexpr 函数必须把所有的东西都放在一个单独的return语句中,而constexpr则无此限制:
constexpr int func(bool flag){ // C++14 和 C++11 均可 return 0; }constexpr int func(bool flag){ // C++11 中不可以, C++14 中可以 if(flag) return 1; else return 0; }
[[deprecated]] 标记
C++14 中增加了 deprecated 标记,修饰类、变量、函数等,当程序中使用了被其修饰的代码的时候,编译时会产生警告,用来提示开发者该标记修饰的内容将来可能会被移除,尽量不要使用。
struct [[deprecated]] A {};
int main(){
A a;
return 0;
}当编译时,会出现如下警告:
~/test$ g++ test.cc -std=c++14
test.cc: In function ‘int main()’:
test.cc:11:7: warning: ‘A’ is deprecated [-Wdeprecated-declarations]
A a;
^
test.cc:6:23: note: declared here
struct [[deprecated]] A {二进制字面量与整形字面量分隔符
C++14 引入了二进制字面量,也引入了分隔符。
int a = 0b0001'0010'1010;
double b = 3.14'1234'1234'1234;std::make_unique
我们都知道 C++11 中有std::make_shared,却没有std::make_unique,在 C++14 中已经完善。
struct A {};
std::unique_ptr<A> ptr = std::make_unique<A>();std::make_timed_mutex 与 std::shared_lock
C++14 通过 std::make_timed_mutex 与 std::shared_lock 来实现读写锁,保证多个线程可以同时读,写操作不可以同时和读操作一起进行。
实现方式如下:
struct ThreadSafe{
mutable std::make_timed_mutex mutex_;
int value_;
ThreadSafe(){
value_ = 0;
}
int get() const {
std::shared_lock<std::shared_timed_mutex> loc(mutex_);
return value_;
}
void increase() {
std::unique_lock<std::shared_timed_mutex> lock(mutex_);
value_ += 1;
}
}timed锁可以带来超时时间。
std::integer_sequence ⭐
template<typename T, T... ints>
void print_sequence(std::integer_sequence<T, ints...> int_seq){
std::cout << "the sequence of size " << int_seq.size() << ": ";
((std::cout << ints << " "), ...);
stdcout << "\n";
}std::integer_sequence 和 std::tuple 的配合使用:
template <std::size_t... Is, typename F, typename T>
auto map_filter_tuple(F f, T& t){
return std::make_tuple(f(std::get<Is>(t))...);
}
template <std::size_t... Is, typename F, typename T>
auto map_filter_tuple(std::index_sequence<Is...>, F f, T& t){
return std::make_tuple(f(std::get<Is>(t))...);
}
template <typename S, typename F, typename T>
auto map_filter_tuple(F&& f, T& t){
return map_filter_tuple(S{}, std::forward<F>(f), t);
}std::exchange
// exchange 的实现
template<class T, class U = T>
constexpr T exchange(T& obj, U&& new_value){
T old_value = std::move(obj);
obj = std::forward<T>(new_value);
return old_value;
}
// new_value 的值给了 obj,而没有对 new_value 赋值。
int main(){
std::vector<int> v;
std::exchange(v, {1, 2, 3, 4});
cout << v.size() << endl;
for(int a: v){
cout << a << " ";
}
return 0;
}std::quoted
C++14 引入 std::quoted 用于给字符串添加双引号
int main(){
string str = "hello world";
cout << str << endl;
cout << std::quoted(str) << endl;
return 0;
}C++17新特性 [3]
构造函数模板推导
在 C++17 前构造一个模板类对象需要指明类型:
pair<int, double> p(1, 2.2); // before C++17C++17 就不需要特殊指定,直接可以推导出类型:
pair p(1, 2.2); // C++17 自动推导
vector v = {1, 2, 3}; // C++17结构化绑定 ⭐
通过结构化绑定,对于tuple、map 等类型,获取相应值会方便很多
std::tuple<int, double> func(){
return std::tuple(1, 2.2);
}
int main(){
auto [i, d] = func();
cout << i << endl;
cout << d << endl;
}void f(){
map<int, string> m = {{0, "a"}, {1, "b"}};
for(const auto& [i, s]: m){
cout << i << " " << s << endl;
}
}
int main(){
std::pair a(1, 2.3f);
auto [i, f] = a;
cout << i << endl;
cout << f << endl;
return 0;
}引用的结构化绑定还可以改变对象的值
int main(){
std::pair a(1, 2.3f);
auto& [i, f] = a;
i = 2;
cout << a.first << endl;
}注意结构化绑定不能应用于constexpr
constexpr auto [x, y] = std::pair(1, 2.3f); // compile error, C++20 可以结构化绑定不仅可以绑定 pair 和 tuple ,还可以绑定数组和结构体等。
int array[3] = {1, 2, 3};
auto [a, b, c] = array;
cout << a << " " << b << " " << c << endl;
// 注意这里的struct的成员一定是要public的
struct Point{
int x, y;
};
Point func(){
return {1, 2};
}
const auto [x, y] = func();这里其实可以实现自定义类的结构化绑定,代码如下:
// 需要实现相关的tuple_size和tuple_element和get<N>方法。
class Entry{
public:
void Init(){
name_ = "name";
age_ = 10;
}
std::string GetName() const { return name_; }
int GetAge() const { return age_; }
private:
std::string name_;
int age_;
}
template <size_t I>
auto get(const Entry& e){
if constexpr (I == 0) return e.GetName();
else if constexpr(I == 1) return e.GetAge();
}
namespace std{
template<> struct tuple_size<Entry> : integral_constant<size_t, 2>{};
template<> struct tuple_element<0, Entry> { using type = std::string; };
template<> struct tuple_element<1, Entry> { using type = int; };
}
int main(){
Entry e;
e.Init();
auto [name, age] = e;
cout << name << " " << age << endl; // name 10
return 0;
}if-switch 语句初始化
C++17 前if语句需要这样写代码:
int a = GetValue();
if(a < 101){
cout << a;
}C++17 之后可以这样:
// if (init; condition)
if(int a = GetValue(); a < 101){
cout << a;
}
string str = "Hi World";
if(auto [pos, size] = pair(str.find("Hi"), str.size()); pos != string::npos){
std::cout << pos << " Hello, size is " << size;
}使用这种方式可以尽可能约束作用域,让代码更简洁,可读性略有下降,但是还好
内联变量
C++17 前只有内联函数,现在有了内联变量,我们印象中 C++ 类的静态成员变量在头文件中是不能初始化的,但是有了内联变量,就可以达到此目的了:
// header file
struct A {
static const int value;
}
inline int const A::value = 10;
// ========= 或者 ===========
struct A {
inline static const int value = 10;
}折叠表达式
C++17 引入了折叠表达式使可变模板编程更方便:
template <typename ... Ts>
auto sum(Ts ... ts){
return (ts + ...);
}
int a = {sum(1, 2, 3, 4, 5)}; // 15
std::string a{"hello "};
std::string b{"world"};
cout << sum(a, b) << endl; // hello worldconstexpr lambda 表达式
C++17 前 lambda 表达式只能在运行时使用,C++17引入了constexpr lambda表达式,可以用于在编译期进行计算。
int main(){ // C++17可编译
constexpr auto lamb = [](int n){ return n * n; };
static_assert(lamb(3) == 9, "a");
}注意:constexpr函数有如下限制:
函数体不能包含汇编语句、goto语句、label、try块、静态变量、线程局部存储、没有初始化的普通变量,不能动态分配内存,不能有new、delete等,不能虚函数。
namespace嵌套
namespace A{
namespace B{
namespace C{
void func();
}
}
}
// C++17,更方便更舒适
namespace A::B::C {
void func();
}__has_include预处理表达式
可以判断是否有某个头文件,代码可能会在不同编译器下工作,不同编译器的可用头文件有可能不同,所以可以用此来判断:
#if defined __has_include
#if __has_include(<charconv>)
#define has_charconv 1
#include <charconv>
#endif
#endif
std::optional<int> ConvertToInt(const std::string& str){
int value{};
#ifdef has_charconv
const auto last = str.data() + str.size();
const auto res = std::from_chars(str.data(), last, value);
if(res.ec == std::errc{} and res.ptr == last) return value;
#else
// alternative implementation...
// 其他的实现方式
#endif
return std::nullopt;
}在lambda表达式中用*this捕获对象副本
正常情况下,lambda表达式中访问类的成员变量需要捕获this,但是这里捕获的是this指针,指向的是对象的引用,正常情况下可能没问题,但是如果多线程情况下,函数的作用域超过了对象的作用域,对象已经被析构,还访问了成员变量,就会有问题。
struct A{
int a;
void func(){
auto f = [this]{
cout << a << endl;
};
f();
}
};
int main(){
A a;
a.func();
return 0;
}所以 C++17 增加了新特性,捕获*this,不持有this指针,而是持有对象的拷贝,这样生命周期就与对象的生命周期不相关了。
struct A{
int a;
void func(){
auto f = [*this]{
cout << a << endl;
};
f();
}
};
int main(){
A a;
a.func();
return 0;
}新增Attribute
我们可能平时在项目中见过__declspec、attribute, #pragma指示符,使用它们来给编译器提供一些额外的信息,来产生一些优化或特定的代码,也可以给其他开发者一些提示信息。
例如:
struct A { short f[3]; } __attribute__((aligned(8)));
void fatal() __attribute__((noreturn));在C++11和C++14中有更方便的方法:
[[carries_dependency]] 让编译期跳过不必要的内存栅栏指令
[[noreturn]] 函数不会返回
[[deprecated]] 函数将弃用的警告
[[noreturn]] void terminate() noexcept;
[[deprecated("use new func instead")]] void func() {}C++17又新增了三个:
[[fallthrough]],用在switch提示可以直接落下去,不需要break,让编译器忽略警告。
switch (i) {
case 1:
xxx; // warning
case 2:
xxx;
[[fallthrough]]; // 消除警告
case 3:
xxx;
break;
}使得编译器和其他开发者都可以理解开发者的意图。
[[nodiscard]]:表示修饰的内容不能被忽略,可用于修饰函数,标明返回值一定要被处理。
[[nodiscard]] int func();
void F(){
func(); // warning 没有处理函数返回值
}[[maybe_unused]]:提示编译器修饰的内容可能暂时没有使用,避免产生警告。
void func1() {}
[[maybe_unused]] void func2() {} // 消除警告
void func3() {
int x = 1;
[[maybe_unused]] int y = 2; // 消除警告
}字符串转换 ⭐
新增from_chars函数和to_chars函数,直接看代码:
#include <charconv>
int main(){
const std::string str{"123456098"};
int value = 0;
const auto res = std::from_chars(str.data(), str.data() + 4, value);
if (res.ec == std::errc()){
cout << value << ", distance " << res.ptr - str.data() << endl;
}else if(res.ec == std::errc::invalid_argument){
cout << "invalid" << endl;
}
str = std::string("12.34");
double val = 0;
const auto format = std::chars_format::general;
res = std::from_chars(str.data(), str.data() + str.size(), value, format);
str = std::string("xxxxxxxx");
const int v = 1234;
res = std::to_chars(str.data(), str.data() + str.size(), v);
cout << str << ", filled " << res.ptr - str.data() << " characters \n";
// 1234xxx, filled 4 characters.
}std::variant
C++17增加了std::variant实现类似union的功能,但却比union更高级,举个例子union里面不能有string这种类型,但std::variant却可以,还可以支持更多复杂类型,如map等,看代码:
int main(){ // C++17可编译
std::variant<int, std::string> var("hello");
cout << var.index() << endl;
var = 123;
cout << var.index() << endl;
try{
var = "world";
std::string str = std::get<std::string>(var); //通过类型获取值
var = 3;
int i = std::get<0>(var); // 通过index获取值
cout << str << endl;
cout << i << endl;
}catch(...){
// xxx
}
return 0;
}注意:一般情况下variant的第一个类型要有对应的构造函数,否则编译失败:
struct A{
A(int i) {}
};
int main(){
std::variant<A, int> var; // 编译失败
}如何避免这种情况,可以使用std::monostate来打个桩,模拟一个空状态。
std::variant<std::monostate, A> var; // 可以编译成功std::optional
我们有时候可能会有需求,让函数返回一个对象,如下:
struct A {};
A func(){
if(flag) return A();
else {
// 异常情况下,怎么返回异常值,想返回一个空
}
}有一种方法是返回对象指针,异常情况下就可以返回nullptr啦,但是这就涉及到了内存管理,也许你会使用智能指针,但是这里更方便的方法就是std::optional啦。
std::optional<int> StoI(const std::string& s){
try{
return std::stoi(s);
}catch(...){
return std::nullopt;
}
}
void func(){
std::string s{"123"};
std::optional<int> o = StoI(s);
if(o){
cout << *o << endl;
}else{
cout << "error" << endl;
}
}std::any ⭐
C++17引入了any可以用来存储任何类型的单个值,见代码:
int main(){ // C++17可编译
std::any a = 1;
cout << a.type().name() << " " << std::any_cast<int>(a) << endl;
a = 2.2f;
cout << a.type().name() << " " << std::any_cast<double>(a) << endl;
a.reset();
if(a.has_value()){
cout << a.type().name();
}
a = std::string("a");
cout << a.type().name() << " " << std::any_cast<std::string>(a) << endl;
}std::apply
使用std::apply可以将tuple展开作为函数参数传入,见代码:
int add(int first, int second) { return first + second; }
auto add_lambda = [](auto first, auto second) { return first + second; }
int main(){
std::cout << std::apply(add, std::pair(1, 2)) << "\n";
std::cout << add(std::pair(1, 2)) << "\n";
std::cout << std::apply(add_lambda, std::tuple(2.0f, 3.0f)) << "\n";
}std::make_from_tuple
使用make_from_tuple可以将tuple展开作为构造函数参数
struct Foo{
Foo(int first, int second, int third){
std::cout << first << " " << second << " " << third << std::endl;
}
};
int main(){
auto tuple = std::make_tuple(42, 3.14f, 0);
std::make_from_tuple<Foo>(std::move(tuple));
}std::string_view
通常我们传递一个string的时候,会触发对象的拷贝操作,大字符串的拷贝赋值操作会触发堆的内存分配,很影响运行效率,有了string_view就可以避免拷贝操作,平时传递过程中传递string_view即可。
void func(std::string_view stv) { cout << stv << endl; }
int main(){
std::string str = "Hello World";
std::cout << str << std::endl;
std::string_view stv(str.c_str(), str.size());
cout << stv << endl;
func(stv);
return 0;
}as_const
C++17使用as_const可以将左值转成const类型
std::string str = "string";
const std::string& constStr = std::as_const(str);file_system
C++17正式将file_system纳入到标准之中,提供了关于文件的大多数功能,基本上应有尽有,这里举几个简单例子
namespace fs = std::filesystem;
fs::create_directory(dir_path);
fs::copy_file(src, dst, fs::copy_options::skip_existing);
fs::exists(filename);
fs::current_path(err_code);std::shared_mutex
C++17引入了shared_mutex,可以实现读写锁
C++20新特性
操作系统
进程、线程和协程[5]
进程
进程是并发执行的程序在执行过程中的分配和资源管理的最小单位,是一个动态概念,竞争计算机系统资源的基本单位。
线程
线程是进程的一个执行单元,是进程内的调度实体。比进程更小的独立运行单位。线程也被称为轻量级进程。
协程
协程是一种用户态的轻量级线程,协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
进程和线程区别
地址空间
线程共享本进程的地址空间,而进程之间是独立的地址空间。
资源
线程共享本进程的资源如内存,I/O,CPU等,不利于资源的管理和保护,而进程之间的资源是独立的,能够很好的进行资源管理和保护。
健壮性
多进程要比多线程健壮,一个进程崩溃之后,在保护模式下不会对其他的进程产生影响,但是一个线程崩溃整个进程都死掉。
执行过程
每个独立的进程有一个程序运行的入口,循序执行序列和程序出口,执行开销大。
但是线程不能独立执行,必须依存在应用程序中,由应用程序提供多个现成的执行控制,执行开销小。
可并发性
两者均可并发执行。
切换时
进程切换时,消耗的资源大,效率不高。所以涉及到频繁的切换时,使用线程要好于进程。同样如果要求同时进行并且又要共享某些变量的并发操作,只能用线程不能用进程。
其他
线程是处理器调度的最小单位,进程不是。
协程与线程进行比较?
- 一个线程可以拥有多个协程,一个进程也可以单独拥有多个协程,这样python中则能使用多核CPU。
- 线程进程都是同步机制,而协程则是异步
- 协程能保留上一次调用时的状态,每次过程重入时,就相当于进入上一次调用的状态
进程间通信的方式
无名管道
速度慢,容量有限,只有父子进程能够通信。
FIFO(有名管道)
去除了管道只能在父子进程中使用的限制
消息队列
信号量
共享内存
什么是僵尸进程?
一个子进程结束后,它的父进程并没有等待它(调用wait或者waitpid),那么这个子进程将成为一个僵尸进程。僵尸进程是一个已经死亡的进程,但是并没有真正被销毁。它已经放弃了几乎所有内存空间,没有任何可执行代码,也不能被调度,仅仅在进程表中保留一个位置,记载该进程的进程ID、终止状态以及资源利用信息(CPU时间,内存使用量等等)供父进程收集,除此之外,僵尸进程不再占有任何内存空间。这个僵尸进程可能会一直留在系统中直到系统重启。
危害:占用进程号,而系统所能使用的进程号是有限的;占用内存。
以下情况不会产生僵尸进程:
- 该进程的父进程先结束了。每个进程结束的时候,系统都会扫描是否存在子进程,如果有则用Init进程接管,成为该进程的父进程,并且会调用wait等待其结束。
- 父进程调用wait或者waitpid等待子进程结束(需要每隔一段时间查询子进程是否结束)。wait系统调用会使父进程暂停执行,直到它的一个子进程结束为止。waitpid则可以加入
WNOHANG(wait-no-hang)选项,如果没有发现结束的子进程,就会立即返回,不会将调用waitpid的进程阻塞。同时,waitpid还可以选择是等待任一子进程(同wait),还是等待指定pid的子进程,还是等待同一进程组下的任一子进程,还是等待组ID等于pid的任一子进程; - 子进程结束时,系统会产生
SIGCHLD(signal-child)信号,可以注册一个信号处理函数,在该函数中调用waitpid,等待所有结束的子进程(注意:一般都需要循环调用waitpid,因为在信号处理函数开始执行之前,可能已经有多个子进程结束了,而信号处理函数只执行一次,所以要循环调用将所有结束的子进程回收); - 也可以用
signal(SIGCLD, SIG_IGN)(signal-ignore)通知内核,表示忽略SIGCHLD信号,那么子进程结束后,内核会进行回收。
什么是孤儿进程?
一个父进程已经结束了,但是它的子进程还在运行,那么这些子进程将成为孤儿进程。孤儿进程会被Init(进程ID为1)接管,当这些孤儿进程结束时由Init完成状态收集工作。
什么是IO多路复用?怎么实现?
IO多路复用(IO Multiplexing)是指单个进程/线程就可以同时处理多个IO请求。
实现原理:用户将想要监视的文件描述符(File Descriptor)添加到select/poll/epoll函数中,由内核监视,函数阻塞。一旦有文件描述符就绪(读就绪或写就绪),或者超时(设置timeout),函数就会返回,然后该进程可以进行相应的读/写操作。
select/poll/epoll三者的区别?
select:将文件描述符放入一个集合中,调用select时,将这个集合从用户空间拷贝到内核空间(缺点1:每次都要复制,开销大),由内核根据就绪状态修改该集合的内容。(缺点2)集合大小有限制,32位机默认是1024(64位:2048);采用水平触发机制。select函数返回后,需要通过遍历这个集合,找到就绪的文件描述符(缺点3:轮询的方式效率较低),当文件描述符的数量增加时,效率会线性下降;poll:和select几乎没有区别,区别在于文件描述符的存储方式不同,poll采用链表的方式存储,没有最大存储数量的限制;epoll:通过内核和用户空间共享内存,避免了不断复制的问题;支持的同时连接数上限很高(1G左右的内存支持10W左右的连接数);文件描述符就绪时,采用回调机制,避免了轮询(回调函数将就绪的描述符添加到一个链表中,执行epoll_wait时,返回这个链表);支持水平触发和边缘触发,采用边缘触发机制时,只有活跃的描述符才会触发回调函数。
总结,区别主要在于:
- 一个线程/进程所能打开的最大连接数
- 文件描述符传递方式(是否复制)
- 水平触发 or 边缘触发
- 查询就绪的描述符时的效率(是否轮询)
什么时候使用select/poll,什么时候使用epoll?
当连接数较多并且有很多的不活跃连接时,epoll的效率比其它两者高很多;但是当连接数较少并且都十分活跃的情况下,由于epoll需要很多回调,因此性能可能低于其它两者。
什么是文件描述符?
文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。
内核通过文件描述符来访问文件。文件描述符指向一个文件。
缺页中断
- 缺页异常:malloc和mmap函数在分配内存时只是建立了进程虚拟地址空间,并没有分配虚拟内存对应的物理内存。当进程访问这些没有建立映射关系的虚拟内存时,处理器自动触发一个缺页异常,引发缺页中断。
- 缺页中断:缺页异常后将产生一个缺页中断,此时操作系统会根据页表中的外存地址在外存中找到所缺的一页,将其调入内存。
说说静态库和动态库的区别是什么[1]
- 静态库代码装载的速度快,执行速度略比动态库快。
- 动态库更加节省内存,可执行文件体积比静态库小很多。
- 静态库是在编译时加载,动态库是在运行时加载。
- 生成的静态链接库,Windows下以.lib为后缀,Linux下以.a为后缀。生成的动态链接库,Windows下以.dll为后缀,Linux下以.so为后缀。
虚拟内存
操作系统为每一个进程分配一个独立的地址空间,这就是虚拟内存。虚拟内存与物理内存存在映射关系,通过页表寻址完成虚拟地址和物理地址的转换。
为什么要用虚拟内存
因为早期的内存分配方法存在以下问题:
- 进程地址空间不隔离。会导致数据被随意修改。
- 内存使用效率低。
- 程序运行的地址不确定。操作系统随机为进程分配内存空间,所以程序运行的地址是不确定的。
使用虚拟内存的好处
- 扩大地址空间。每个进程独占一个4G空间,虽然真实物理内存没那么多。
- 内存保护:防止不同进程对物理内存的争夺和践踏,可以对特定内存地址提供写保护,防止恶意篡改。
- 可以实现内存共享,方便进程通信。
- 可以避免内存碎片,虽然物理内存可能不连续,但映射到虚拟内存上可以连续。
什么是死锁?
在两个或者多个并发进程中,每个进程持有某种资源而又等待其它进程释放它们现在保持着的资源,在未改变这种状态之前都不能向前推进,称这一组进程产生了死锁(deadlock)。
死锁产生的必要条件?
- 互斥:一个资源一次只能被一个进程使用;
- 占有并等待:一个进程至少占有一个资源,并在等待另一个被其它进程占用的资源;
- 非抢占:已经分配给一个进程的资源不能被强制性抢占,只能由进程完成任务之后自愿释放;
- 循环等待:若干进程之间形成一种头尾相接的环形等待资源关系,该环路中的每个进程都在等待下一个进程所占有的资源。
有哪些页面置换算法?
在程序运行过程中,如果要访问的页面不在内存中,就发生缺页中断从而将该页调入内存中。此时如果内存已无空闲空间,系统必须从内存中调出一个页面到磁盘中来腾出空间。页面置换算法的主要目标是使页面置换频率最低(也可以说缺页率最低)。
- 最佳页面置换算法OPT(Optimal replacement algorithm):置换以后不需要或者最远的将来才需要的页面,是一种理论上的算法,是最优策略;
- 先进先出FIFO:置换在内存中驻留时间最长的页面。缺点:有可能将那些经常被访问的页面也被换出,从而使缺页率升高;
- 第二次机会算法SCR:按FIFO选择某一页面,若其访问位为1,给第二次机会,并将访问位置0;
- 时钟算法 Clock:SCR中需要将页面在链表中移动(第二次机会的时候要将这个页面从链表头移到链表尾),时钟算法使用环形链表,再使用一个指针指向最老的页面,避免了移动页面的开销;
- 最近未使用算法NRU(Not Recently Used):检查访问位R、修改位M,优先置换R=M=0,其次是(R=0, M=1);
- 最近最少使用算法LRU(Least Recently Used):置换出未使用时间最长的一页;实现方式:维护时间戳,或者维护一个所有页面的链表。当一个页面被访问时,将这个页面移到链表表头。这样就能保证链表表尾的页面是最近最久未访问的。
- 最不经常使用算法LFU(Least Frequently Used):置换出访问次数最少的页面
计算机网络
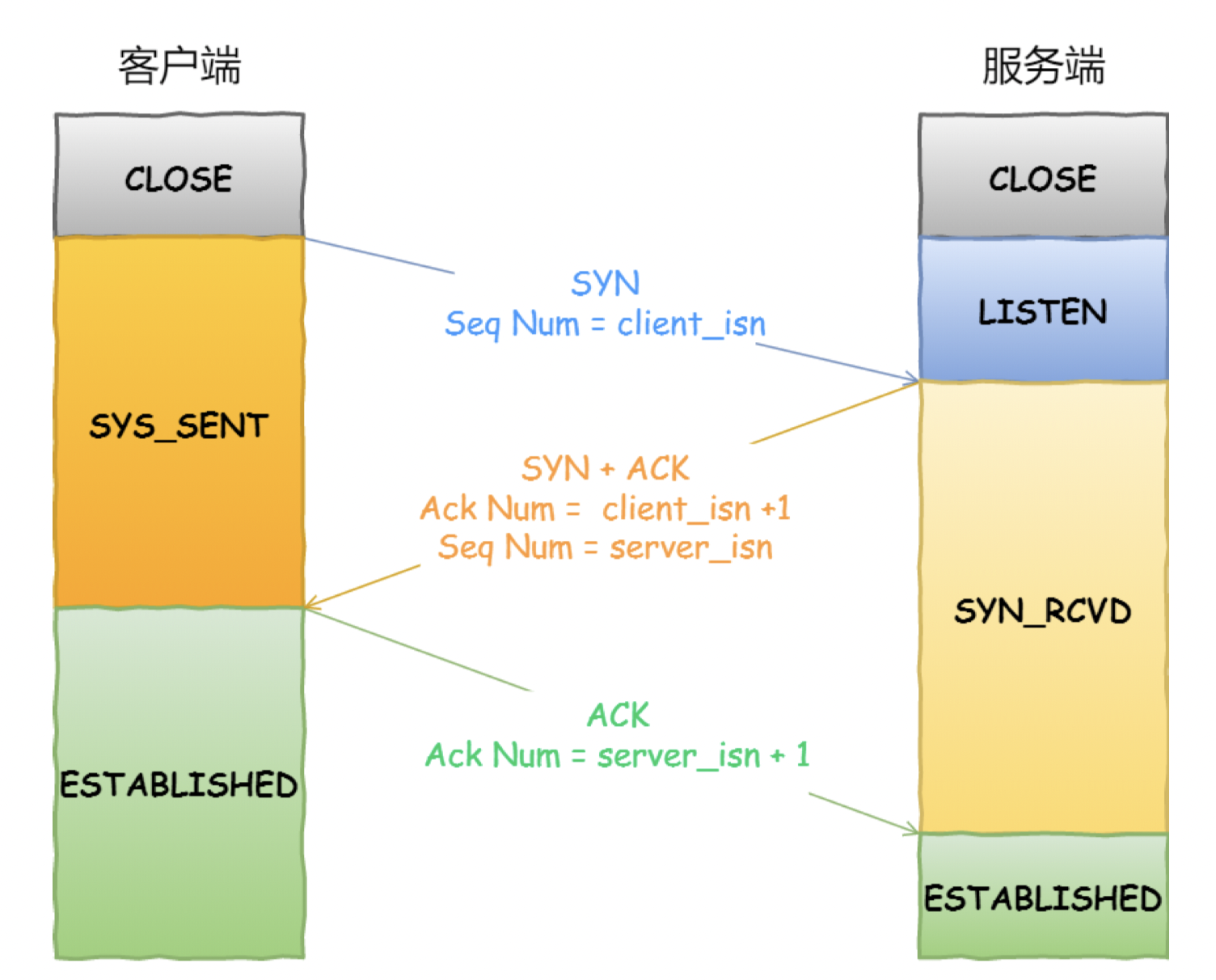
什么是三次握手 (three-way handshake)?
- 第一次握手:Client将SYN置1,随机产生一个初始序列号seq发送给Server,进入SYN_SENT状态;
- 第二次握手:Server收到Client的SYN=1之后,知道客户端请求建立连接,将自己的SYN置1,ACK置1,产生一个acknowledge number=sequence number+1,并随机产生一个自己的初始序列号,发送给客户端;进入SYN_RCVD状态;
- 第三次握手:客户端检查acknowledge number是否为序列号+1,ACK是否为1,检查正确之后将自己的ACK置为1,产生一个acknowledge number=服务器发的序列号+1,发送给服务器;进入ESTABLISHED状态;服务器检查ACK为1和acknowledge number为序列号+1之后,也进入ESTABLISHED状态;完成三次握手,连接建立。
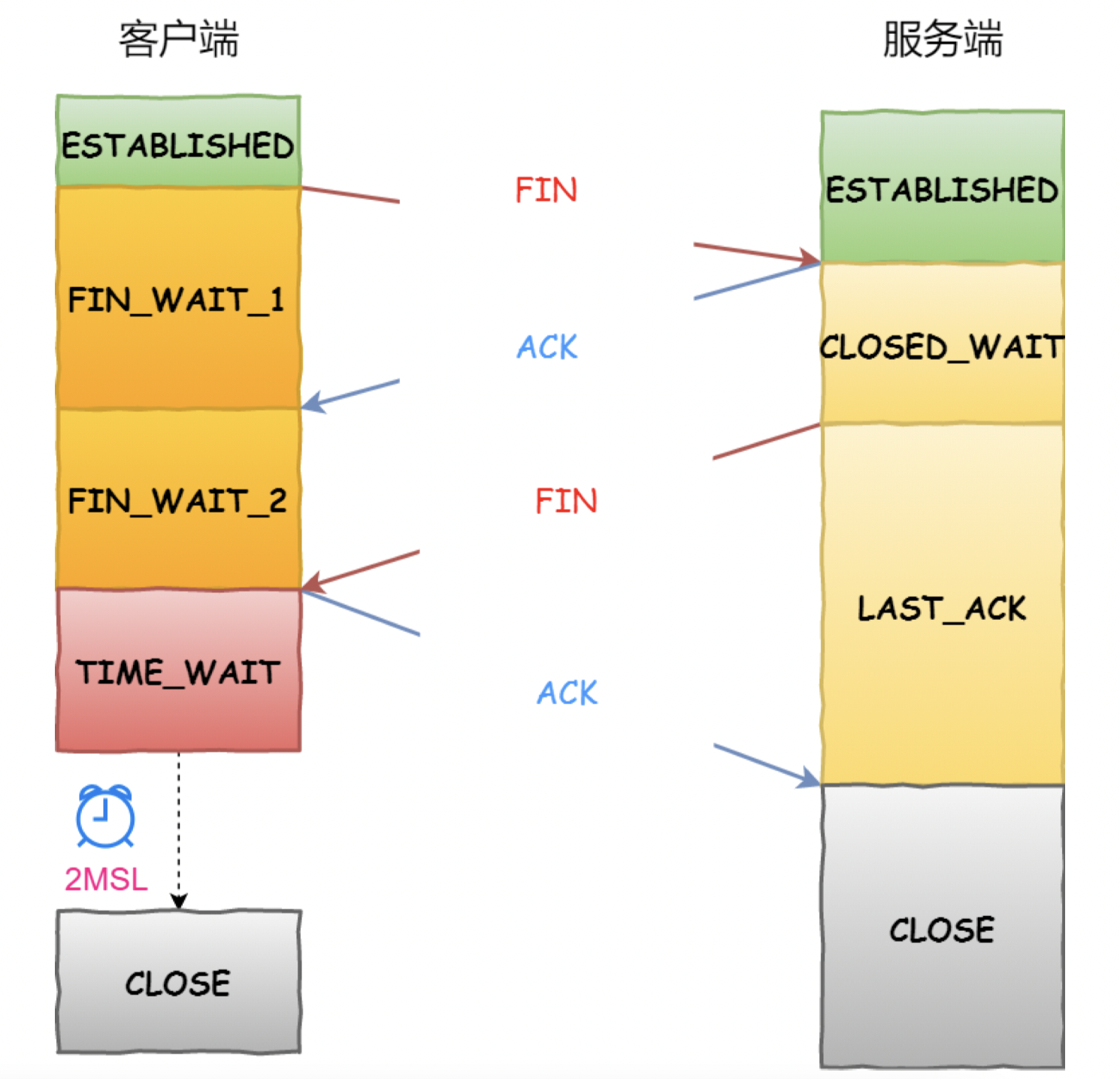
什么是四次挥手?
- 第一次挥手:Client将FIN置为1,发送一个序列号seq给Server;进入FIN_WAIT_1状态
- 第二次挥手:Server收到FIN之后,发送一个ACK=1,acknowledge number=收到的序列号+1;进入CLOSE_WAIT状态。此时客户端已经没有要发送的数据了,但仍可以接受服务器发来的数据
- 第三次挥手:Server将FIN置1,发送一个序列号给Client;进入LAST_ACK状态
- 第四次挥手:Client收到服务器的FIN后,进入TIME_WAIT状态;接着将ACK置1,发送一个acknowledge number=序列号+1给服务器;服务器收到后,确认acknowledge number后,变为CLOSED状态,不再向客户端发送数据。客户端等待2*MSL(报文段最长寿命)时间后,也进入CLOSED状态。完成四次挥手
TCP与UDP
- TCP是面向连接的,UDP是无连接的
- TCP是可靠的,UDP不可靠
- TCP只支持点对点通信,UDP支持一对一、一对多、多对一、多对多
- TCP是面向字节流的,UDP是面向报文的
- TCP有拥塞控制机制,UDP没有。网络出现的拥塞不会使源主机的发送速率降低,这对某些实时应用是很重要的,比如媒体通信,游戏
- TCP首部开销(20字节)比UDP首部开销(8字节)要大
- UDP的主机不需要维持复杂的连接状态表
拥塞控制
拥塞控制主要由四个算法组成:慢启动(Slow Start)、拥塞避免(Congestion voidance)、快重传 (Fast Retransmit)、快恢复(Fast Recovery)
- 慢启动:刚开始发送数据时,先把拥塞窗口(congestion window)设置为一个最大报文段MSS的数值,每收到一个新的确认报文之后,就把拥塞窗口加1个MSS。这样每经过一个传输轮次(或者说是每经过一个往返时间RTT),拥塞窗口的大小就会加倍
- 拥塞避免:当拥塞窗口的大小达到慢开始门限(slow start threshold)时,开始执行拥塞避免算法,拥塞窗口大小不再指数增加,而是线性增加,即每经过一个传输轮次只增加1MSS.
- 快重传:快重传要求接收方在收到一个失序的报文段后就立即发出重复确认(为的是使发送方及早知道有报文段没有到达对方)而不要等到自己发送数据时捎带确认。快重传算法规定,发送方只要一连收到三个重复确认就应当立即重传对方尚未收到的报文段,而不必继续等待设置的重传计时器时间到期。
- 快恢复:当发送方连续收到三个重复确认时,就把慢开始门限减半,然后执行拥塞避免算法。不执行慢开始算法的原因:因为如果网络出现拥塞的话就不会收到好几个重复的确认,所以发送方认为现在网络可能没有出现拥塞。
也有的快重传是把开始时的拥塞窗口cwnd值再增大一点,即等于ssthresh + 3*MSS。这样做的理由是:既然发送方收到三个重复的确认,就表明有三个分组已经离开了网络。这三个分组不再消耗网络的资源而是停留在接收方的缓存中。可见现在网络中减少了三个分组。因此可以适当把拥塞窗口扩大些。
TCP如何保证传输的可靠性
- 数据包校验
- 对失序数据包重新排序(TCP报文具有序列号)
- 丢弃重复数据
- 应答机制:接收方收到数据之后,会发送一个确认(通常延迟几分之一秒);
- 超时重发:发送方发出数据之后,启动一个定时器,超时未收到接收方的确认,则重新发送这个数据;
- 流量控制:确保接收端能够接收发送方的数据而不会缓冲区溢出
HTTPS 通讯流程[6]
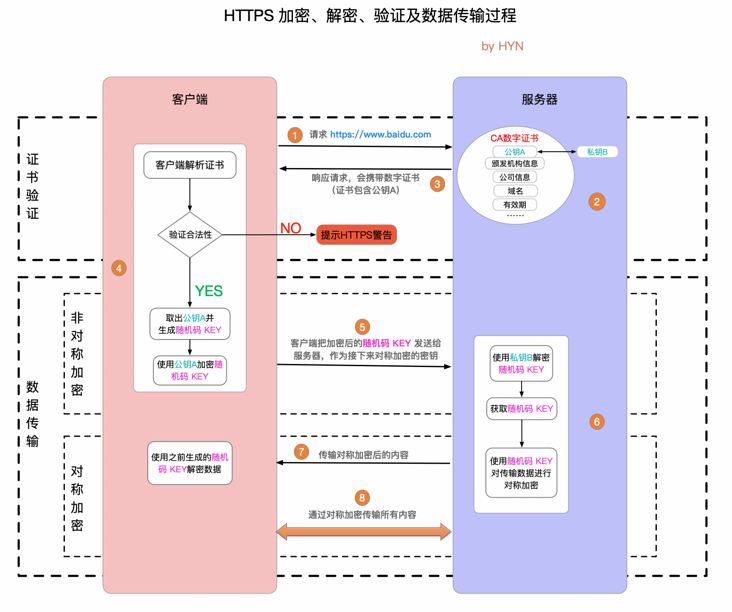
看上去眼花缭乱,不要怕,且听我细细道来。HTTPS的整个通信阶段可以分为两大阶段:证书验证阶段和数据传输阶段,数据传输阶段又可以分为非对称加密阶段和对称加密阶段。具体流程按图中的序号讲解如下:
- 客户端请求HTTPS网址,然后连接到Server的443端口(HTTPS默认的端口,类似于HTTP的80端口)。
- 采用HTTPS协议的服务器必须要有一套数字CA(Certification Authority)证书,证书是需要申请的,并由专门的数字证书认证机构(CA)通过非常严格的审核之后颁发的电子证书(当然了是要钱的,安全级别越高价格越贵)。颁发证书的同时会产生一个私钥和公钥。私钥由服务端自己保存,不可泄露。公钥则是附带在证书的信息中,可以公开的。证书本身也附带了一个证书电子签名,这个签名用来验证证书的完整性和真实性,可以防止证书被篡改。
- 服务器响应客户端请求,将证书传递给客户端,证书中包含公钥和大量其他信息,比如证书颁发机构信息、公司信息和证书有效期等。Chrome浏览器点击地址栏的锁标志再点击证书就可以看到证书的详细信息了。
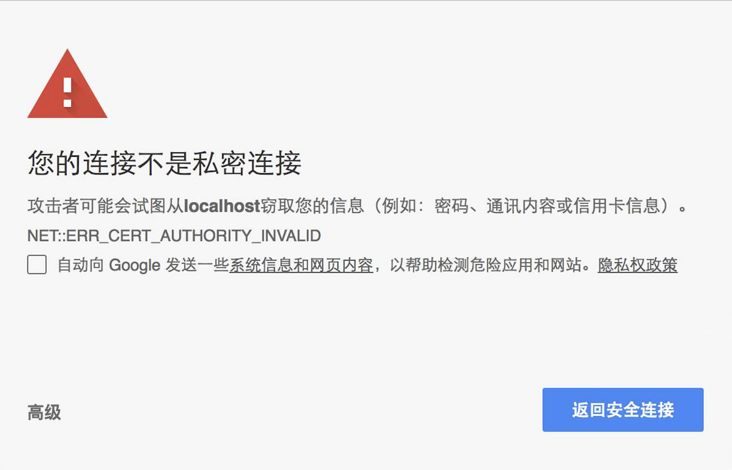
- 客户端解析证书并对其进行验证。如果证书不是由可信机构颁布,或者证书中的域名与实际域名不一致,或者证书已经过期,就会向访问者显示一个警告,由其选择是否还要继续通信,就像下面这样:
如果证书没有问题,客户端就会从服务器证书中取出服务器的公钥A。然后客户端还会生成一个随机码KEY,并使用公钥A将其加密。 - 客户端把加密后的随机码KEY发送给服务器,作为后面对称加密的密钥。
- 服务器在收到随机KEY之后,会使用私钥B将其解密。经过以上这些步骤,客户端和服务器终于建立了安全连接,完美解决了对称加密的密钥泄露问题,接下来就可以用对称加密愉快地进行通信了。
- 服务器使用密钥(随机码KEY)对数据进行对称加密并发送给客户端,客户端使用相同的密钥(随机码KEY)解密数据。
- 双方使用对称加密愉快地传输所有数据。
Redis
Redis的数据类型
- String:字符串类型,最简单的类型
- Hash:类似于Map的一种结构。
- List:有序列表。
- Set:无序集合。
- ZSet:带权值的无序集合,即每个ZSet元素还另有一个数字代表权值,集合通过权值进行排序。
Redis数据持久化
为了能够重用Redis数据,或者防止系统故障,我们需要将Redis中的数据写入到磁盘空间中,即持久化。
Redis提供了两种不同的持久化方法可以将数据存储在磁盘中,一种叫快照RDB,另一种叫只追加文件AOF。
RDB
在指定的时间间隔内将内存中的数据集快照写入磁盘(Snapshot),它恢复时是将快照文件直接读到内存里。
优势:适合大规模的数据恢复;对数据完整性和一致性要求不高
劣势:在一定间隔时间做一次备份,所以如果Redis意外down掉的话,就会丢失最后一次快照后的所有修改。
AOF
以日志的形式来记录每个写操作,将Redis执行过的所有写指令记录下来(读操作不记录),只许追加文件但不可以改写文件,Redis启动之初会读取该文件重新构建数据,换言之,Redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
AOF采用文件追加方式,文件会越来越大,为避免出现此种情况,新增了重写机制,当AOF文件的大小超过所设定的阈值时, Redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集.。
优势
- 每修改同步:appendfsync always 同步持久化,每次发生数据变更会被立即记录到磁盘,性能较差但数据完整性比较好
- 每秒同步:appendfsync everysec 异步操作,每秒记录,如果一秒内宕机,有数据丢失
- 不同步:appendfsync no 从不同步
劣势
相同数据集的数据而言AOF文件要远大于RDB文件,恢复速度慢于RDB
AOF运行效率要慢于RDB,每秒同步策略效率较好,不同步效率和RDB相同
简述缓存雪崩
缓存雪崩指缓存中一大批数据到过期时间,而从缓存中删除。但该批数据查询数据量巨大,查询全部走数据库,造成数据库压力过大。
软件设计模式
说说什么是单例设计模式,如何实现
单例模式定义
保证一个类仅有一个实例,并提供一个访问它的全局访问点,该实例被所有程序模块共享。
那么我们就必须保证:
- 该类不能被复制。
- 该类不能被公开的创造。
那么对于C++来说,它的构造函数,拷贝构造函数和赋值函数都不能被公开调用。
单例模式实现方式
单例模式通常有两种模式,分别为懒汉式单例和饿汉式单例。两种模式实现方式分别如下:
- 懒汉式设计模式实现方式(2种)
- 静态指针 + 用到时初始化
- 局部静态变量
- 饿汉式设计模式(2种)
- 直接定义静态对象
- 静态指针 + 类外初始化时new空间实现
编译原理
C/C++程序编译从代码到可执行程序
C++和C语言类似,一个C++程序从源码到执行文件,有四个过程,预编译、编译、汇编、链接。
- 预编译:这个过程主要的处理操作如下:
- 将所有的#define删除,并且展开所有的宏定义
- 处理所有的条件预编译指令,如#if、#ifdef
- 处理#include预编译指令,将被包含的文件插入到该预编译指令的位置。
- 过滤所有的注释
- 添加行号和文件名标识。
- 编译:这个过程主要的处理操作如下:
- 词法分析:将源代码的字符序列分割成一系列的记号。
- 语法分析:对记号进行语法分析,产生语法树。
- 语义分析:判断表达式是否有意义。
- 代码优化:
- 目标代码生成:生成汇编代码。
- 目标代码优化:
- 汇编:这个过程主要是将汇编代码转变成机器可以执行的指令。
- 链接:将不同的源文件产生的目标文件进行链接,从而形成一个可以执行的程序。
链接分为静态链接和动态链接。
静态链接,是在链接的时候就已经把要调用的函数或者过程链接到了生成的可执行文件中,就算你在去把静态库删除也不会影响可执行程序的执行;生成的静态链接库,Windows下以.lib为后缀,Linux下以.a为后缀。
而动态链接,是在链接的时候没有把调用的函数代码链接进去,而是在执行的过程中,再去找要链接的函数,生成的可执行文件中没有函数代码,只包含函数的重定位信息,所以当你删除动态库时,可执行程序就不能运行。生成的动态链接库,Windows下以.dll为后缀,Linux下以.so为后缀。